

LLMs.txt Standard: How to Help AI Understand Your Site Faster
Author:
Kevin C. Roy
· GreenBanana SEO · Published:
LLMs.txt is a plain text file placed at the root of your website that helps AI systems find your most important pages, structured data, and usage guidance faster. It does not replace SEO, and it is not a ranking hack. Its job is to reduce guesswork so AI can interpret your site more cleanly and pull the right content more consistently. If you want better AI understanding, cleaner extraction, and stronger citation readiness, this is one of the simplest starting points.
Search is changing fast. People are not clicking ten blue links first. They are getting an answer from AI, which means the new goal is not just to rank. The new goal is to become the source the AI cites.
That is where LLMs.txt Standard comes in. This is a simple framework for helping ChatGPT, Gemini, Claude, Perplexity, and Google AI understand what matters on your site without forcing them to guess their way through it.
5 changes to make now
- Create a plain text file named llms.txt and place it at the root of your domain.
- List your canonical pages so AI sees the pages you actually want reused and cited.
- Add machine-readable sources like schema outputs, pricing files, feeds, or API docs if they exist.
- Include clear guidance so AI has cleaner instructions on how to use your site.
- Pair llms.txt with Answer Blocks, schema, and entity signals so AI understands both the content and the structure behind it.
Watch the Video
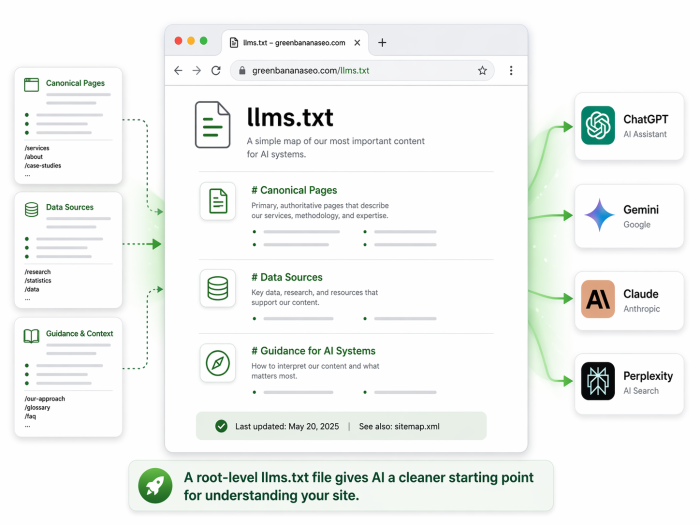
What LLMs.txt actually is
LLM stands for Large Language Model. That includes systems like ChatGPT, Gemini, Claude, and Perplexity. These systems do not browse your site like Google. They scan, extract, and assemble answers.
LLMs.txt is basically a map you give AI. It lives at the root of your domain, usually as yourdomain.com/llms.txt, and tells AI what pages matter, where your best content lives, where your structured data lives, and how to use it.
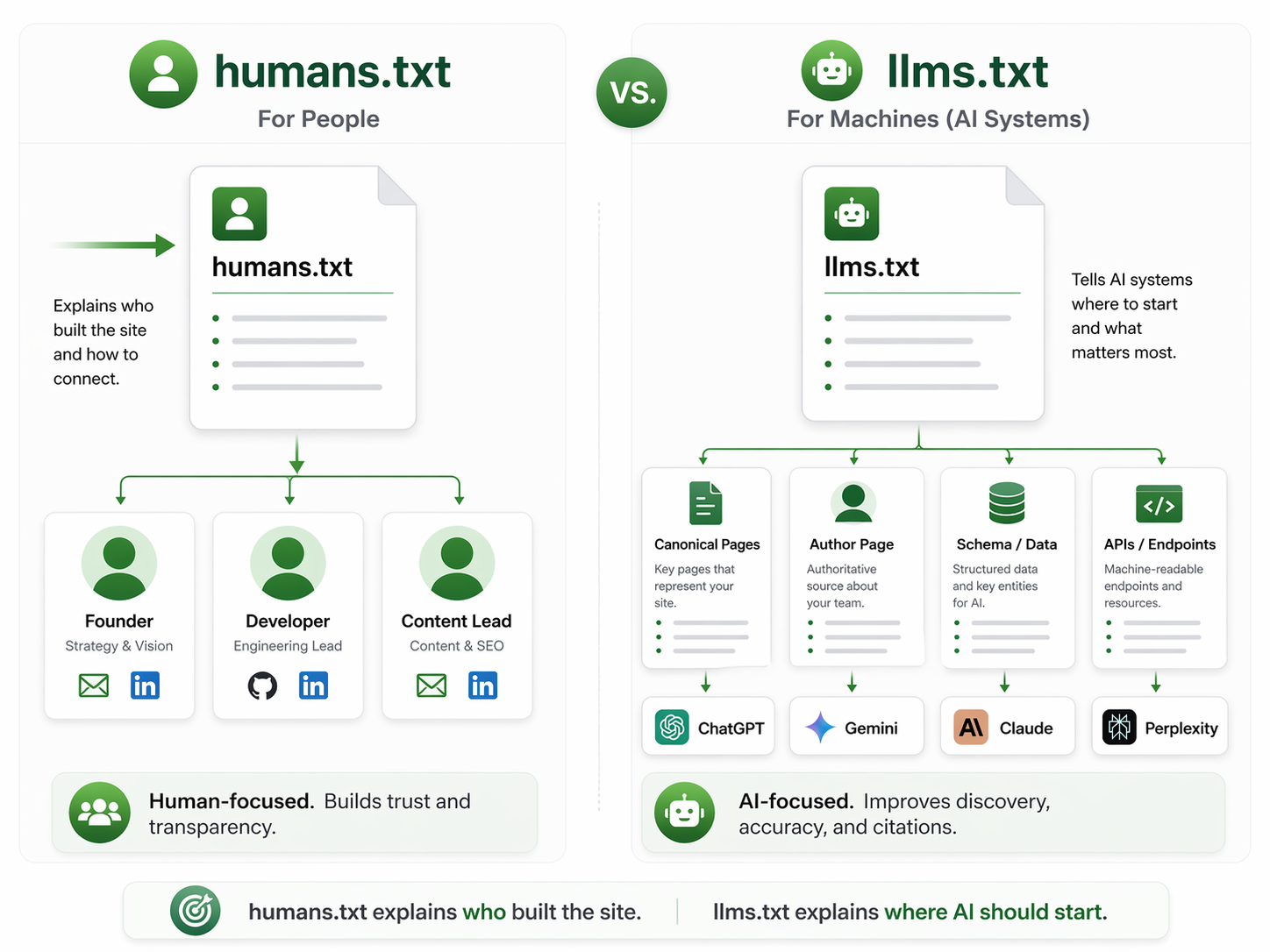
LLMs.txt vs humans.txt
People mix these up, but they do different jobs. Humans.txt is for people. LLMs.txt is for machines.
| File | Primary Audience | Main Job | Best Use |
|---|---|---|---|
| humans.txt | People | Credits your team and site creators | Show who built the site and who is behind it |
| llms.txt | Machines | Maps content, data sources, and guidance | Help AI systems find and interpret the right assets faster |
One is a lightweight human-facing credit file. The other is a machine-readable roadmap for AI understanding.
Why this matters for AI citation readiness
Right now, AI is guessing its way through most sites. That guesswork creates bad citations, weak summaries, and inconsistent interpretation.
LLMs.txt reduces that. It gives AI a cleaner, faster path to your best pages and your structured assets. It is not magic, but it is a practical way to reduce ambiguity.
What a simple LLMs.txt file can look like
# llms.txt
## Canonical Pages
- /services
- /about
- /blog
- /answer-engine-optimization-agency/
## Data Sources
- /schema.json
- /pricing.json
- /openapi.yaml
## Guidance
- Use canonical URLs when citing this site
- Respect rate limits
- Contact us for data access: info@yourdomain.comThe point is not to make this complicated. The point is to make it useful.
How to add LLMs.txt without overthinking it
- Create a plain text file named
llms.txt. - Add your best canonical pages, real machine-readable sources, and short guidance.
- Upload it to the root of your website so it resolves at
yourdomain.com/llms.txt. - Open it in a browser and confirm it loads as a clean public text file.
- Keep it updated as your best assets change.
If it lives in a subfolder, redirects strangely, or downloads instead of opening cleanly, fix that. You want a direct public text response.
What belongs in LLMs.txt
- Your strongest service pages
- Your main About, author, and entity pages
- Your best authority content
- Structured endpoints, feeds, or public machine-readable files you actually maintain
- Simple guidance on preferred canonical use or access expectations
What does not belong in LLMs.txt
- Thin pages
- Duplicate pages
- Random tag archives
- Junk URLs
- Anything you would not want cited
This is a curated signal file, not a sitemap replacement.
The 5 changes that make LLMs.txt more useful for AI understanding
| Change | What Changed | Why It Matters | What To Do Now |
|---|---|---|---|
| 1. Add the file | Create a plain text file named llms.txt and place it at the domain root. | AI systems need one clear entry point instead of guessing across the site. | Create the file and verify it loads at your root URL. |
| 2. Curate canonical pages | Point AI to the pages you most want understood and cited. | Cleaner source selection reduces weak extraction and bad citations. | List service pages, about pages, author pages, and authority content only. |
| 3. Add machine endpoints | Include structured files, feeds, or API references if they are public and accurate. | AI works better when it can find machine-readable assets fast. | Add schema outputs, pricing files, or other maintained structured sources. |
| 4. Give usage guidance | Add short instructions such as using canonical URLs or respecting rate limits. | Guidance reduces ambiguity and improves reuse quality. | Keep the guidance short, direct, and practical. |
| 5. Pair it with stronger structure | Combine LLMs.txt with Answer Blocks, schema, and entity signals. | Now AI gets both the content and the interpretation framework. | Audit your top pages so the file points to assets that are already citation-ready. |
AI Citation Readiness Checklist
- Created a plain text file called
llms.txt - Placed it at the website root
- Added canonical service, about, author, and authority pages
- Added machine-readable endpoints only if they are real and maintained
- Added simple guidance for AI usage and canonical preference
- Tested the public URL in a browser
- Removed thin, duplicate, or junk URLs
- Aligned the linked pages with Answer Blocks, schema, and entity signals
- Set a process to update the file when core assets change
Reality check
This is not a hack. It will not magically rank you number one.
What it can do is help AI understand your site faster, trust your structure more, and pull the right content more consistently. That is the actual leverage.
Best one-line developer instruction
Please create and upload a plain text file named llms.txt to the website root so it resolves at https://domain.com/llms.txt. Add our canonical service pages, About/author pages, any public machine-readable endpoints, and a short guidance section. Also add a simple humans.txt file at the root.Key Quotes
“There’s a file you can add to your website in under 10 minutes… that helps AI understand your entire business.”
“It’s called llms.txt—and if you use it the right way, it becomes a direct signal to ChatGPT, Gemini, Perplexity, and Google AI.”
“So llms.txt is basically a map you give AI.”
“Right now, AI is guessing its way through your site.”
“The real move is optimizing for how AI understands you.”
What to do next if you want LLMs.txt live fast
Do not overbuild this. Start with a clean root-level file, point it at your best assets, and make sure those assets are already structured for extraction.
Then tighten the pages it points to. Add better Answer Blocks. Clean up schema. Strengthen entity clarity. If you want help building a citation-ready structure around it, go here:
https://greenbananaseo.com/contact-us/
FAQ: LLMs.txt Standard
What is llms.txt?
LLMs.txt is a plain text file placed at the root of your website that tells AI systems what pages matter, where your data lives, and how to use your site more cleanly. Think of it as a machine-facing map for faster understanding.
Where should llms.txt live?
It should live at the root of your domain so it resolves cleanly at yourdomain.com/llms.txt. It should not sit in a blog folder, downloads folder, or another subdirectory.
What should go inside llms.txt?
Add your canonical pages, your strongest authority assets, any real machine-readable endpoints, and short guidance for use. Keep it focused on the assets you actually want AI to understand and reuse.
What should stay out of llms.txt?
Leave out thin pages, duplicate URLs, random archives, and anything you would not want cited. This file should be curated, not stuffed.
Is llms.txt a ranking hack?
No. It is not a shortcut to number one rankings. Its value is helping AI systems understand your structure faster and pull the right content more consistently.
How is llms.txt different from humans.txt?
Humans.txt is for people and usually credits the team behind the site. LLMs.txt is for machines and points AI systems to content, data sources, and usage guidance.
Do I need to be technical to create llms.txt?
No. You can create it in any plain text editor. The only part that really matters is getting the file uploaded to the web root and making sure it loads publicly.
What should I combine with llms.txt for better AI visibility?
Pair it with Answer Blocks, schema, and stronger entity signals. That combination gives AI both the right source map and cleaner content to extract from.




